Information is abundant, an ever-growing pile of little bits of data that drives every aspect of your life, and the bigger that pile of data grows, the more valuable it becomes to yourself or others. For example, consider a situation where you need to search the internet for a specific piece of information, such as how to create a MySQL database. To do this, you would send a query to a search engine, which then parses large sets of data to find the relevant results. Putting all that data into some form of useful context manually, such as inputting it into spreadsheet software, is time-consuming.
Using databases, it is easier to automate the input and processing of data. Now you can store all that data into ever-growing databases and push, pull, squeeze, and tug on the data to get information from it that you could never dream of getting before, and in the blink of an eye. A database is an organized collection of structured data. The data becomes information once it is processed. For example, you have a database to store servers and their information, such as processor count, memory, storage, and location. Alone, this data is not immediately useable for business decisions and analysis. However, detailed reports about the utilization of servers at specific locations contain the information that can be fetched from the database.
To ensure fast and accurate access and to protect all the valuable data, the database is usually housed in an external application specifically designed to efficiently store and manage large volumes of data. MySQL is one such application. In almost all cases, the database management system or database server is installed on a dedicated computer. This way, many users can connect to a centralized database server at the same time. Irrespective of the number of users, both the data and the database are important—as sensitive data and useful insights are stored in it—and must be suitably protected and efficiently used. For example, a database can be used to store log information or the revenue of a company.
In this book, you will build up your knowledge to manage your database. You will also learn how to deploy, manage, and query the database as you progress in the book.
The following section will describe databases in greater depth.
Database architecture
A database is a collection of related data that has been gathered and stored for easy access and management. Each discrete item of data in a database is, in itself, not very useful or valuable, but the entire collection of data as a whole (when coupled with ease of use and fast access) provides an exceptionally powerful tool for business and personal use. For example, if you have a set of data that shows how much time a user spends on a specific page, you can track user experience on your application. As the volume of data grows and its historical content stretches further back in time, the data becomes more useful in identifying and predicting past and future trends, and the value of the data to its owner increases. Databases allow the user to logically separate data and store it in a well-structured format that allows them to create reports and identify trends.
To understand the advantage of databases, consider a telephone book that is used to store people's names, addresses, and phone numbers. A phone book is a good example of a manual data store, in which data is organized alphabetically to find the information easily (albeit, manually). With a phone book, storing large sets of data creates a bulky physical object, which must be manually searched to find the data we want. The process of searching the data is time-consuming, and we can only search the data by name since this is how it is organized.
To help improve this process, you can utilize computer-based information systems to store the data either in tables or flat files. Flat files store data in a plain text format. Files with the extensions .csv or .txt are usually flat files.
Figure 1.1 – An example of a flat file
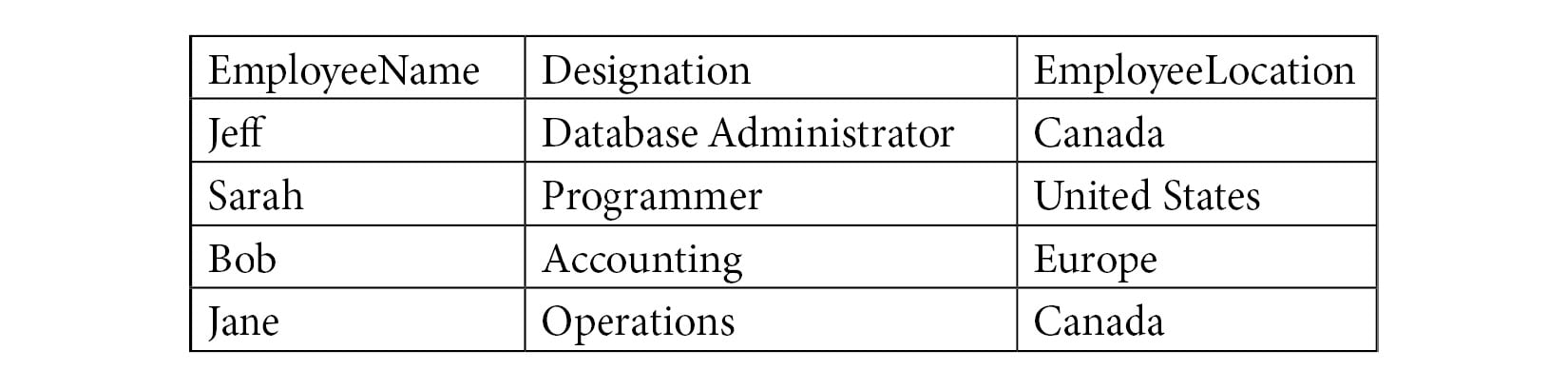
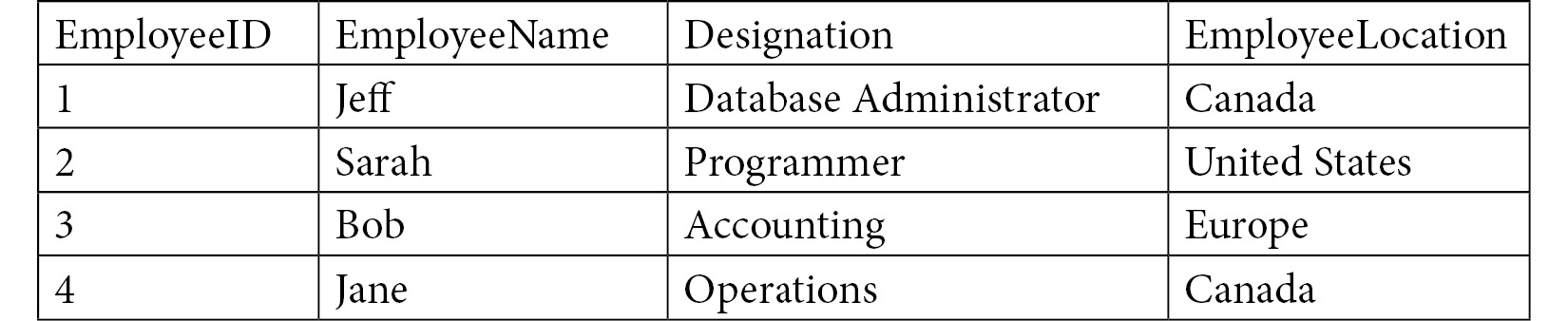
Tables store data in rows and columns, allowing you to logically separate data and store them.
Figure 1.2 – An example of a table
You use databases in almost everything you do in your life. Whenever you connect to a website, the screen layout and the information displayed in front of the screen are fetched from the database. The cell phone you use in your day-to-day life stores the contact numbers in a database. When you watch a show on a streaming service, your login details, the information about the show, and the show itself are stored in a database.
There are many different types of database systems out there. Most are quite similar in some ways, though quite different in others. Some are geared toward a specific type of activity, and others are more general in their application. You will look at the two most common database management systems used by businesses today, DBMS and RDBMS, in the upcoming sections.
A centralized database is one that is located, stored, and maintained at a single site. The simplest example of a centralized database is an MS Access file stored on SharePoint that is used by multiple people. A distributed database is more complex as the data is not stored in a single place, but rather at multiple locations. A distributed database helps users to fetch the information quickly as the data is stored closer to the end users.
For example, if you have a database that is distributed across America, Europe, and Asia, American users will access the database stored in America, European users will access the one stored in Europe, and so on. However, this does not mean that Americans cannot access data in Europe or Asia. It's just that accessing data closer to them is faster.
Relational and object-based databases are ideas as to how the data is stored behind the scenes. Relational databases include databases such as MySQL and MSSQL, whereas object databases include databases such as PostgreSQL. Relational databases use the concept of the relational database model explained in this chapter, while object-based databases use the concept of intelligent objects and object-oriented programming, where the elements know what their purpose is and what they are intended to be used for.
In the next section, you will look at a few examples of common database management solutions used by developers.
MS Access as a database
MS Access is a database application from Microsoft. It is one of the simplest examples of a database. It allows users to manipulate data with macro functions, queries, and reports, to be able to share it via different visualization techniques, such as graphs and Venn diagrams. It is a number cruncher and is excellent for analyzing numbers, forecasting, and performing what-if scenarios.
Figure 1.3 – MS Access file
However, MS Access is not the best database available, due to certain limitations in terms of functionality. For example, if offices of your company are present at multiple locations, it is possible to share an Access database. However, there is a limit to the number of users who can connect at a single time. In addition, there are limitations on the size of Access database files, making it only possible to store limited datasets. Access works best in situations where the groups accessing the database are small, and also the dataset is small, within the range of 1 million records or less.
Take, for example, a situation where an insurance company is creating a database for customer service to access customer data for insurance policies. If the team starts small, with 3 customer service agents and 300 records, MS Access works well, since the scope of usage is limited. However, as the company grows, more customer service agents may be added, and more records may be created. As the database grows, MS Access becomes less practical and eventually, Access will no longer work for the application.
Because of these limitations, alternative database management systems are preferred.
Database management system
A database management systems (DBMSs) aim to provide its end users with fine-tuned access to data based in a controlled environment. These systems allow you to define and manage data in a more structured manner. There are many different types of DBMSs used in applications, each with distinct pros and cons. When selecting a DBMS, it is important to determine the best choice for a given problem.
Take the previous example of an insurance company creating a database for customer service agents. If the developers wanted to transition away from MS Access, they could store data within a generic DBMS. These systems can help to organize data in a similar fashion to the Access database, while removing the size and connection caps created by Access. This solves the problem of the database system being limited; however, there are still limitations in terms of the data's structure based on the generic DBMS solution. Some DBMS solutions will simply organize data in tabular formats without any structural advantages. These situations are less ideal for large sets of data. These issues can be eliminated by relational database management systems (RDBMSs).
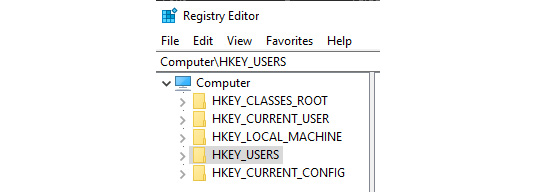
Examples of DBMS include your computer's filesystem, FoxPro, and the Windows Registry.
Figure 1.4 – Windows Registry is an example of a basic DBMS
RDBMS
A relational database stores data in a well-structured format of rows, columns, and tables. A row contains a set of data related to a single entity. A column contains data about a single field or descriptor of the data point. Take, for example, a table that contains user data. Each row will contain data about a single user. Each column will describe the user, storing data points such as their username, password, and similar information. Different types of relationships can be defined between tables, and specific rules enforced on columns. This is an improved version of the DBMS concept and was introduced in 1970. It was designed to support client-server hierarchy, multiple concurrent users or application access, security features, transactions, and other facilities that make working with data from these systems not just safe but efficient as well.
An RDBMS is more robust than a general DBMS or MS Access database. With the insurance database example, you can now create a structure around the data being stored for the customer service representatives. This structure represents the relationships between different datasets, making it easier to draw conclusions from related data. Additionally, you still get all the advantages of a DBMS, giving you the best system to fit your needs.
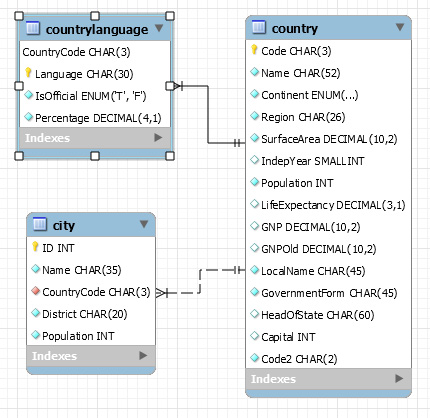
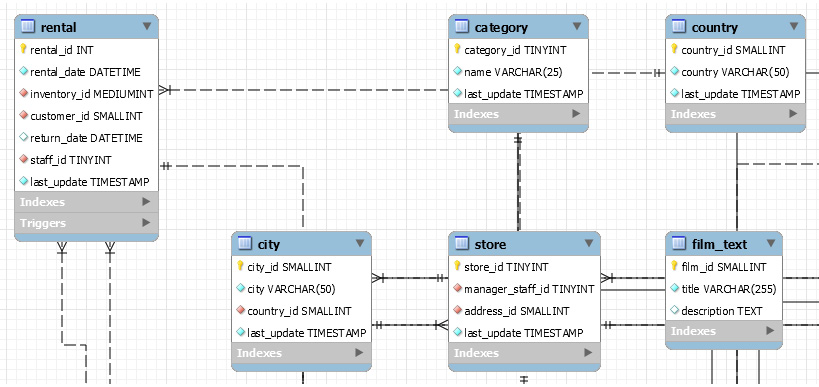
The following figure is an example of a database in MySQL. As you can see, the database has multiple tables (countrylanguage, country, and city), and these tables are linked to each other. You will learn how to link different tables later in Chapter 10, MS Access, Part 2.
Figure 1.5 – RDBMS entity relationship diagram
Some popular RDBMS systems are MySQL, Microsoft SQL Server, and MariaDB. You will learn about MySQL in the following section.
 Argentina
Argentina
 Australia
Australia
 Austria
Austria
 Belgium
Belgium
 Brazil
Brazil
 Bulgaria
Bulgaria
 Canada
Canada
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 France
France
 Germany
Germany
 Great Britain
Great Britain
 Greece
Greece
 Hungary
Hungary
 India
India
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Russia
Russia
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Spain
Spain
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine
 United States
United States